
Reduce_inversion_count
题目如下:
Time Limit: 10000ms
Case Time Limit: 1000ms
Memory Limit: 256MB
Description
Find a pair in an integer array that swapping them would maximally decrease the inversion count of the array. If such a pair exists, return the new inversion count; otherwise returns the original inversion count.
Definition of Inversion: Let (A[0], A[1] … A[n]) be a sequence of n numbers. If i < j and A[i] > A[j], then the pair (i, j) is called inversion of A.
Example:
Count(Inversion({3, 1, 2})) = Count({3, 1}, {3, 2}) = 2
InversionCountOfSwap({3, 1, 2})=>
{
InversionCount({1, 3, 2}) = 1 <– swapping 1 with 3, decreases inversion count by 1
InversionCount({2, 1, 3}) = 1 <– swapping 2 with 3, decreases inversion count by 1
InversionCount({3, 2, 1}) = 3 <– swapping 1 with 2 , increases inversion count by 1
}
Input
Input consists of multiple cases, one case per line.Each case consists of a sequence of integers separated by comma.
Output
For each case, print exactly one line with the new inversion count or the original inversion count if it cannot be reduced.
Sample In
3,1,2
1,2,3,4,5
Sample Out
1
0
首先题目给了逆序数的定义,给定序列(A[0], A[1] … A[n]),若i<j,并且A[i]>A[j],则(i,j)称为A的一个逆序。然后问存不存在一个数对,使得将这个数对交换之后,新的序列的逆序数减小的最大。
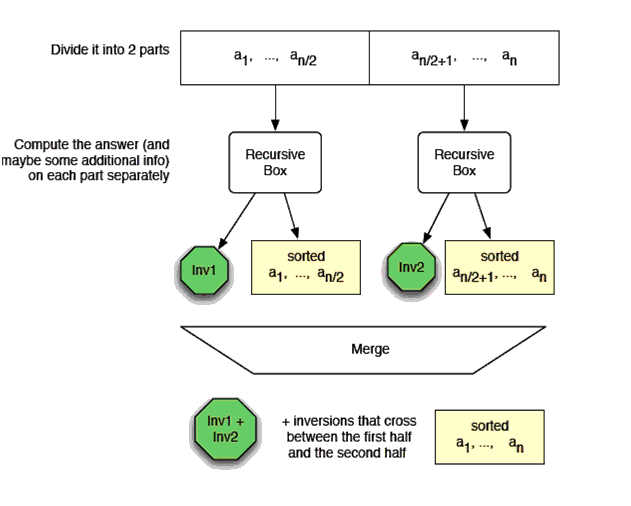
首先我们要先求得序列的逆序数,可以直接暴力求解,即使用两层循环进行计算,时间复杂度为O(n*n)。或者采用归并排序进行求解。我们知道,在归并排序中,将两个排好序的数组进行merge的时候,是依次比较两个数组中的元素,将较小的存放在一个临时的数组中,最后再复制到原来的数组中,加入我们已经知道了前后两部分数组各自的逆序数inv1和inv2,是不是只要把两者相加就得到了合并之后的数组的逆序数呢?答案是否定的。因为在merge的过程中逆序数也发生了变化。所以我们需要把lnv1和lnv2以及inv_merge相加才能得到最后的逆序数。那么问题就来了,我们如何得到在merge过程中的逆序数呢?我们举个例子来说明。
在merge的过程中,假设使用i来索引前半部分的数组,使用j来索引后半部分的数组,如果a[i]>a[j],就会存在mid-i个逆序。因为前后两个数组都是排好序的,如果a[i]>a[j],那么a[i]到a[mid-1]都是大于a[j]的(mid为指向后半部分数组第一个元素)。
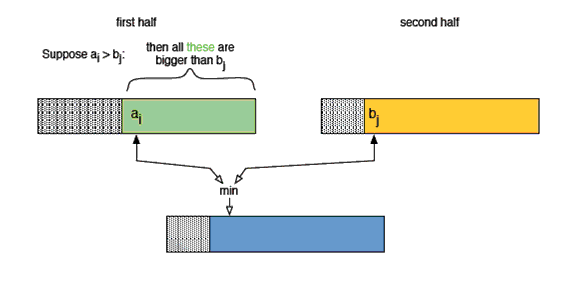
完整的过程如下图所示:
这一步骤在代码中的表现,只是需要merge函数中的a[i]>a[j]这个条件下统计所有的逆序数,再加上递归得到的前后两部分数组的逆序数,即可求出整个数组的逆序数。
逆序数是求完了,可是这道题目还没有结束,题目要求的是交换一个数对使得逆序数减少的最大,我们再一次想到了使用两层嵌套循环来交换,分别计算每次交换后的逆序数,保存最小的,可是这个方法的时间复杂度实在太高,仔细想想,就会发现,并不是所有的交换都会使得逆序数减小,当i<j时,只有在a[i]>a[j]的情况下,交换两个数才能使得逆序数减小,如果a[i]<a[j]的情况下交换a[i]和a[j]会导致逆序数增加。这样一来通过增加一个判断语句使得工作量减少了一些,可是这还不够,能不能不用每次都计算交换之后的逆序数呢?
我们仔细观察交换前后逆序数的变化,可以发现,当在a[i]>a[j]时交换两者之后,对于a[k](K<i)和a[k](K>i)的数是没有影响的,受到影响的只有a[k](i<K<j)。当a[k](i<K<j)的值在不同的范围的时候,对于逆序数的影响也是不一样的,这里分为3种情况( 前提a[i]>a[j],a[i]和a[j]交换导致的逆序数减少不算 ):
(1)a[k] < a[j] 或者 a[k] > a[i]时,逆序数不变。
(1)a[k] = a[j] 或者 a[k] = a[i]时,逆序数减少1。
(1)a[j] < a[k] < a[i]时,逆序数减少2。
举个例子,以a[i] = 7,a[j] = 4为前提,如果a[k] = 3或者9时,交换前这3个数的逆序数为1,交换之后为1(之前说了,a[i]和a[j]交换导致的逆序数减少不算),没有变化;如果a[k] = 4或者7时,交换前这3个数的逆序数为1,交换之后为0,减少了1;如果a[k] = 5时,交换前这3个数的逆序数为2,交换之后为0,减少了2。
这样我们便可以不用每次都去话费nlogn的时间去计算逆序数,只需要在第一次计算逆序数之后,每次统计交换前后逆序数的减少量,保留逆序数减少的最大的值,最后用初始的逆序数减去减少的最大量,就得到了题目要求的结果了。
##源代码
/****************************************************************************
* @file answer.c
* @brief 参见description。
* @version V1.00
* @date 2014.5.1
* @note
****************************************************************************/
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
/**
* @brief 归并排序函数实现从小到大排序。
* @param[in] array 原始数组指针
* @param[in] temp 用于存放排序的数组
* @param[in] begin 数组起始位置
* @param[in] end 数组结束位置
* @retval
* @see None
* @note
*/
int MergeSort(int *array, int *temp, int begin, int end)
{
int inv_count = 0; //记录逆序数
if(NULL == array || NULL == temp )
{
printf("参数错误!\n");
return -1;
}
int mid;
if(begin < end)
{
//将数组分成两部分,分别进行归并排序,再将两个排好序的数组进行合并
mid = (begin + end)/2;
inv_count = MergeSort(array, temp, begin, mid);
inv_count += MergeSort(array, temp, mid + 1, end);
inv_count += Merge(array, temp, begin, mid + 1, end);
}
return inv_count;
}
/**
* @brief 归并排序函数实现从小到大排序。
* @param[in] array 原始数组指针
* @param[in] temp 用于存放排序的数组
* @param[in] begin 数组起始位置
* @param[in] mid 第二个数组起始位置
* @param[in] end 数组结束位置
* @retval 错误码 0代表成功 1代表参数错误
* @see None
* @note
*/
int Merge(int *array, int *temp, int begin, int mid, int end)
{
if(NULL == array || NULL == temp )
{
printf("参数错误!\n");
return -1;
}
int inv_count = 0;
int i = begin;
int j= mid;
int k = begin;
//将两个数组依次进行比较,把小的存放至temp数组,再将temp数组拷贝至array
while((i <= mid - 1) && (j <= end))
{
if(array[i] <= array[j])
{
temp[k++] = array[i++];
}
else
{
inv_count += mid - i;
temp[k++] = array[j++];
}
}
//拷贝剩余的元素到缓冲区temp
while(i <= mid-1)
{
temp[k++] = array[i++];
}
while(j <= end)
{
temp[k++] = array[j++];
}
//将temp中排好序的数据复制到array中
for(i = begin; i <= end; i++)
{
array[i] = temp[i];
}
return inv_count;
}
int main()
{
int i,j,k,decrease,max,inv_count,num,arr_num;
char *str = (char*)malloc(100*sizeof(char));
int *SourceArray = (int*)malloc(100*sizeof(int));
while(scanf("%s", str) != EOF)
{
i = j = num = 0;
while(str[i] != '\0')
{
if(str[i] >= '0' && str[i] <= '9')
{
num *= 10;
num += str[i] - '0';
}
else
{
SourceArray[j++] = num;
num = 0;
}
str[i++] = '\0';
}
SourceArray[j++] = num;
arr_num = j;
int *temp = (int*)malloc(arr_num*sizeof(int));
int *copy = (int*)malloc(arr_num*sizeof(int));
memcpy(copy,SourceArray,arr_num*sizeof(int));
//printf("当前逆序数的个数为:%d \n",inv_count = MergeSort(copy,temp,0,arr_num-1));
inv_count = MergeSort(copy,temp,0,arr_num-1);
max = 0;
for(i = 0; i < arr_num-1; i++)
{
for(j = i + 1; j < arr_num; j++)
{
if(SourceArray[i] <= SourceArray[j])
continue;
decrease = 1;
//影响的是i和j之间的数,即i+1到j-1
for(k = i + 1; k < j; k++)
{
if((SourceArray[k] < SourceArray[i]) && (SourceArray[k] > SourceArray[j]))
{
decrease = decrease + 2;
}
if(SourceArray[k] == SourceArray[i] || SourceArray[k] == SourceArray[j])
{
decrease++;
}
}
if(decrease > max)
{
max = decrease;
}
}
}
printf("%d\n",inv_count - max);
free(temp);
free(copy);
temp = copy = NULL;
}
free(str);
str = NULL;
}